Performing Advance Analytics in NBFCs using Data Lake and Customer 360 using Feature Store on AWS cloud environment
May 2023 | 8-minute read

Tagged: AIinNBFCs | DataAnalytics | LendingTechnology | DigitalTransformation | CreditRiskAssessment | AWSMigration | MachineLearning | DataLake | KPIFeatureStore | MLOps | AWSIntegration | DataManagement | NBFCIndustry | Customer360 | CloudSolutions
Modern NBFCs, both startups & SMBs in India, are leveraging the power of Artificial Intelligence to give their businesses an edge over traditional lending businesses. All operations from application development (mobile apps and websites) for lending to credit risk assessment, digital KYC & loan disbursal, and follow-ups (refer to figure 1) are done through automated/semi-automated systems.
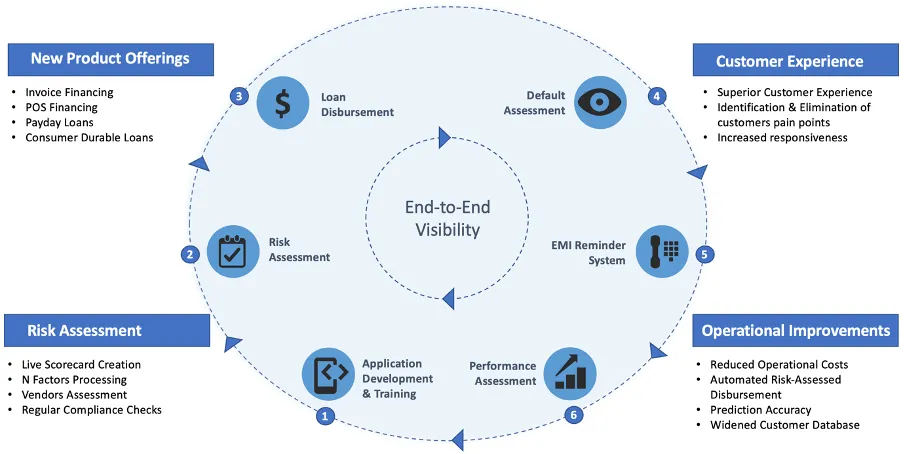
Figure 1: NBFCs leveraging AI across various functions of a lending process
These companies leverage the entire Data Analytics framework across various stages of their operations. The key to deciding potential actions through the customer journey depends on the drivers of the process and the possible decisions. Figure 2 represents a sample view of how businesses leverage analytics across different paths of the process chain. While each potential step can be further deep dived into multiple processes and sub-process of its own, in this blog, we will focus on how these operations can be scaled and unified from a single governance point of view.
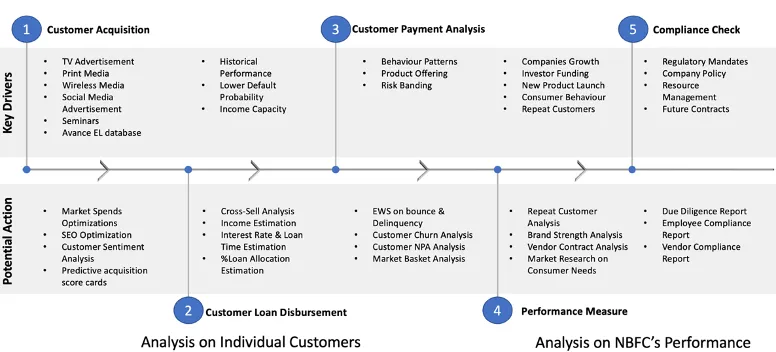
Figure 2: Key drivers and potential actions using analytics across various stages of operations
These operations have been proven effective in bringing the expected edge in the lending business and have improved operating margins. However, as the companies are growing in scale, they are faced with new challenges like
- Data size is increasing multi folds due to growing customer base and transactions which is adding stress to on-prem infrastructure leading to slower processing
- New avenues of data collected across various systems and channels (GPS data, banking statements etc.) requiring the purchase of different storage mediums
- Since various models are built, processing for the features of models often duplicates across departments adding additional load to available infrastructure and increase in governance costs
NBFCs can solve these problems by migrating their workloads to the AWS cloud environment. It will be a one-stop solution for all their operational issues (w.r.t., infrastructure). AWS ecosystem allows businesses to operate with
- Ease of integration with other disparate source systems
- Quick to deploy and scale analytical models in production
- Unlimited storage of all data types with no upfront cost expenditure (pay-as-you-go pricing model)
- Amazon SageMaker has options like “Feature Store”, where businesses can create a single source of all KPIs, which the machine learning models can use
By following the process mentioned in figure 3, companies can build a single source of truth and avenue to build scalable, efficient machine learning models with minimal governance expenses.

Figure 3:3-step process to build efficient, scalable ML practice in organisations
The first step to designing these architectures would be identifying the factors impacting various stages. Businesses need to go back to their drawing boards and build hypotheses that are mutually exclusive and collectively exhaustive (MECE). Companies can create this in collaboration with various stakeholders in the industry or by approaching consulting partners (who can bring knowledge of different companies across geography to achieve goals).
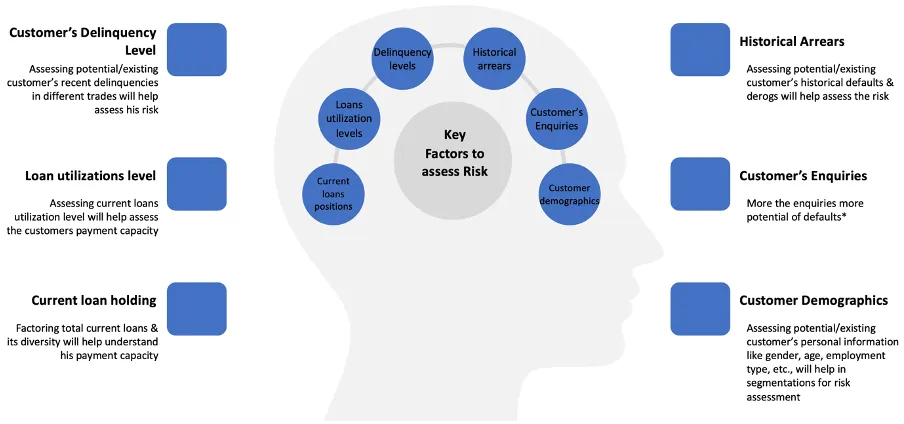
Figure 4:Representation of an approach to create factor buckets impacting businesses
Once the factors are identified, the business can identify the data sources available (typically, Bureau data, Experian data, internal transaction, and KYC data). They can also work with vendors providing other metadata information like user cookies information and app usage data. All these data points need to be sourced into a single Data Lake environment on Amazon Simple Storage Service (S3) using native AWS ETL tools or external APIs/Plugins available. AWS ecosystem allows easy connection to any data sources and types (txt, xml, jpeg, png, mp4 and many more) to and from the AWS environment.
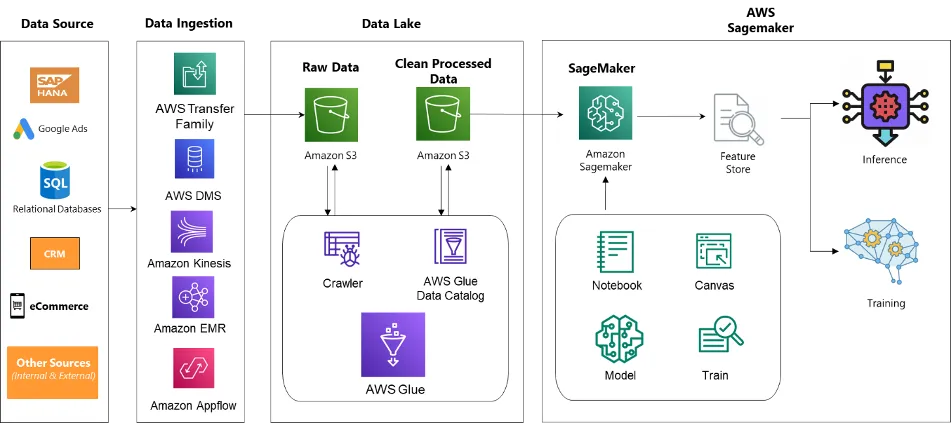
Figure 5:Data Lake Architecture on AWS Cloud for disparate input sources
Once the data is created, business can the create single source of processed KPIs on Amazon SageMaker using its feature store capabilities.
There would be 5 major components in the architecture
- Data Sources — We could multiple source system including ERP systems, relational databases used by applications, CRM platforms, eCommerce websites & even flat files from FTP servers or user-managed files.
- Data Ingestion — AWS provides various services to migrate data in different frequency modes (Real-time, near-real time & batch mode) based on your needs
- AWS Transfer Family — Easily manage file transfers and modernize your transfer workflows within hours by using your existing authentication systems.
- AWS Database Migration Service (DMS) — homogenous/heterogeneous migration of a terabyte-sized database at a low cost, paying only for the compute resources and additional log storage used during the migration process.
- Amazon Kinesis makes it easy to collect, process, and analyze real-time, streaming data so you can get timely insights and react quickly to new information.
- Amazon EMR — Easily run and scale Apache Spark, Hive, Presto, and other big data workloads.
- Amazon AppFlow is a fully managed integration service for transferring data between software as a service (SaaS) application (for example, Salesforce, Zendesk, Slack, and ServiceNow) and AWS services.
3. Data Lake — Single source of truth using Amazon Simple Storage Service (S3) as a storage layer. Migrate raw data from sources to Amazon S3 and then perform data cleaning to store clean data with proper data quality checks.
4. AI/ML — Amazon SageMaker is one-stop solution for your modelling needs. You can manage your entire MLOps lifecycle on Amazon SageMaker as shown in the image below
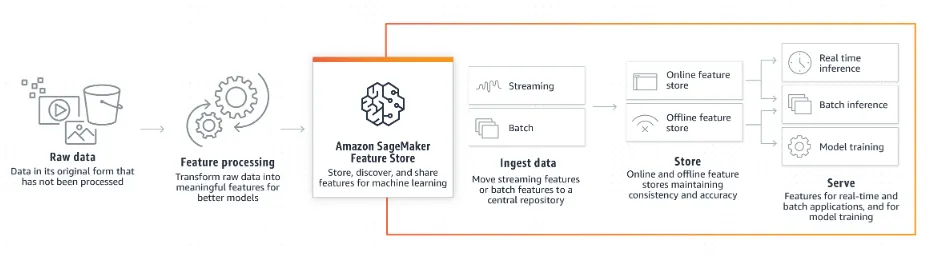
Figure 6:Explains features of Amazon SageMaker Feature Store
Amazon SageMaker Feature store modes
Offline Features: Offline store is primarily intended for batch predictions and model training. The offline store can help you store and serve features for exploration and model training.
Online Features: Online store is designed for supporting real-time predictions that need low millisecond latency reads and high throughput writes.
Benefits of MLOps
Adopting MLOps practices gives you faster time-to-market for ML projects by delivering the following benefits.
Productivity: Providing self-service environments with access to curated data sets lets data engineers and data scientists move faster and waste less time with missing or invalid data.
Repeatability: Automating all the steps in the MLDC helps you ensure a repeatable process, including how the model is trained, evaluated, versioned, and deployed.
Reliability: Incorporating CI/CD practices allows for the ability to not only deploy quickly but with increased quality and consistency.
Auditability: Versioning all inputs and outputs, from data science experiments to source data to trained model, means that we can demonstrate exactly how the model was built and where it was deployed.
Data and model quality: MLOps lets us enforce policies that guard against model bias and track changes to data statistical properties and model quality over time.
Conclusion:
NBFCs can leverage the Data Lake on AWS cloud, which would act as a single source of truth, enabling virtually unlimited scale without worrying about infrastructure management and upfront costs. Using the KPI Feature store of Amazon SageMaker, NBFCs can reduce up to 10K + annual person-hours in feature engineering, re-deploy the same features across various Machine Learning Models and perform customer 360.
I urge the readers of this blog to check out these features on Amazon SageMaker and set your organisation’s Machine Learning practice in fast-track mode with AWS cloud.
To learn more about Ganit and its solutions, reach out at info@ganitinc.com.


